In the previous post, I described a moment in a workflow automation demo that stopped me and forced me to ask a question. That question followed me back to GitHub Copilot, a tool I'd been using for months, And I realised I couldn't answer it there either.
I'd been treating Copilot exactly like a very fast junior developer. useful for the repetitive parts, worth checking before committing anything important. I wasn't thinking about what it was doing underneath. I was thinking about whether the output looked right.
Then it made it obvious.
I was working on a detailed integration design, drafting sample code to illustrate how two systems would talk to each other. I gave Copilot the context. What came back wasn't a completion of what I'd started. It was a choice. It had picked an integration pattern, made an assumption about error handling, and implemented both before I'd specified either.
The code was good. That was the unsettling part. It had read the context and made a design decision on my behalf.
Impressed and unsettled in equal measure. Impressed because it worked. Unsettled because I realised the same question from that demo applied here too: who designed this? In the demo, nobody could answer it. Here, the answer was: the model did. And I had no idea how.
That's when I stopped treating Copilot as autocomplete and started asking the question I should have asked much earlier: what is this thing actually doing underneath? Because if a tool can make a design decision on my behalf, I need to understand how it's making that decision, not just whether the output looks right.
What the Model Is Actually Doing
At its core, an LLM is a prediction machine. It predicts the next most likely token based on patterns learned from vast amounts of training data. It is not retrieving facts from a database. It is not searching. It is predicting what comes next based on what it has seen before.
This distinction sounds academic until you hit the consequences of ignoring it.
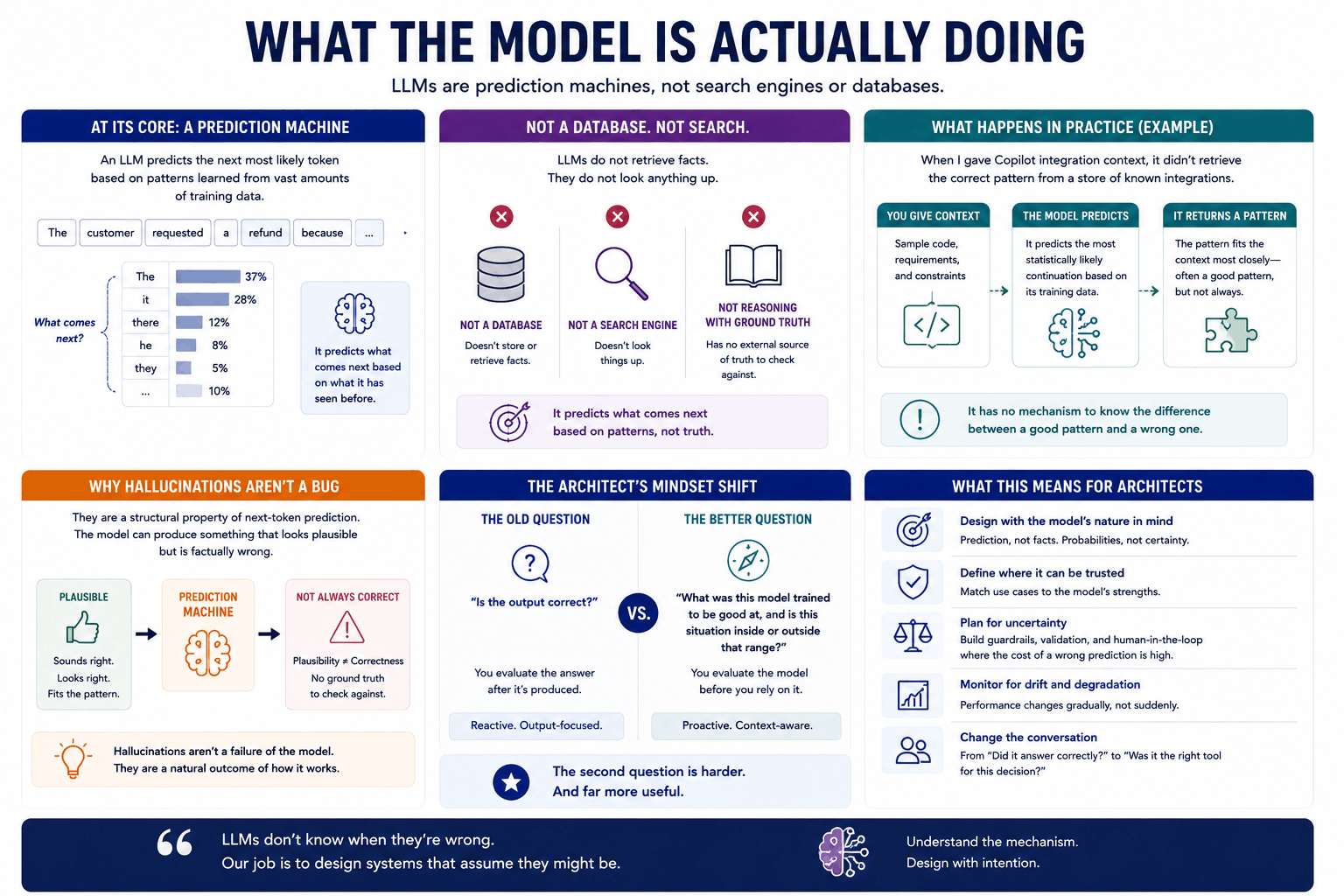
When I gave Copilot that integration context, it didn't retrieve the correct pattern from a store of known integrations. It predicted the most statistically likely continuation of the code I'd started, given everything in its training data. The pattern it chose was the one that fit the context most closely — which, most of the time, is also a good pattern. But not always. And critically, it has no mechanism to know the difference.
This is why hallucinations aren't a bug. They're a structural property. A system that predicts the next likely token will occasionally predict something plausible that is also wrong — because plausibility and correctness are not the same thing, and the model has no ground truth to check against.
For an architect, this reframing changes the question you ask. You stop asking is the output correct? and start asking what was this model trained to be good at, and is this situation inside or outside that range? Those are different questions. The second one is harder and more useful.
The Spectrum — and Where the Real Risk Lives
Not all AI is the same problem. There is a spectrum, and most enterprise conversations I have been in collapse it into two ends. The danger lives in the middle.
Scripted automation sits at one end. Rule-based, deterministic, brittle at the edges. It automates the known and breaks on anything it was not designed for. Fully predictable. Governable with traditional tools.
Assisted intelligence is one step up. Intelligent classification, document routing, smart tagging. The model makes a call — high confidence goes this way, low confidence goes to a human — but within a structured flow. This is where most enterprise AI projects actually live. Still largely predictable. Still auditable.
Contextual judgement is where Copilot was operating in that moment. Not following a rule. Not routing to a pre-defined path. Reading enough context to make a choice that was never pre-specified. The output looks like the previous tier. The behaviour is fundamentally different.
Agentic systems sit at the far end. These don't make a single judgement call inside a structured flow. They perceive an environment, build a plan, execute a sequence of actions, and adapt when something changes. Goals, not instructions.
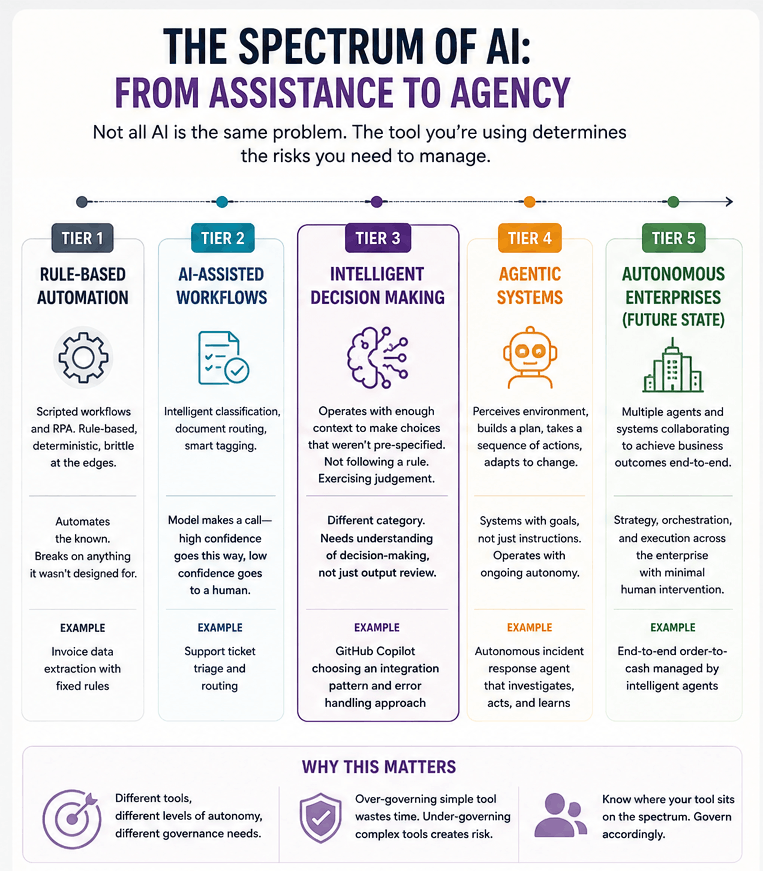
I was using a Contextual Judgement tool and governing it like an Assisted Intelligence one. That gap is where most of the confusion in enterprise AI conversations lives, and it has a real cost. When you under-govern a tool that exercises judgement, you do not notice the problem until a confident, fluent, structurally sound output turns out to be subtly wrong in a way that only surfaces downstream. By then the decision has been made.
The question is not whether to add more governance. It is whether the governance you have is calibrated to the level of autonomy the tool is actually operating with.
What AI Literacy Actually Means for an Architect
The literacy I am describing is not a data scientist's literacy. You do not need to understand gradient descent or transformer architecture at an implementation level. The frame I find useful is the tour guide — you do not speak every language fluently, but you know enough to point people in the right direction, recognise when something has changed, and translate between what someone needs and what is available.
Practically, for me, it came down to three things.
The first is knowing what the model can and cannot do in your specific context — not in general. The models I work with are extraordinarily capable at code generation, pattern recognition, and synthesis. They are genuinely unreliable at anything requiring real-time information, precise numerical reasoning, or retrieval of specific facts. Knowing which side of that line your use case sits on is a design decision, not a technical detail.
The second is knowing where it fails non-obviously. The obvious failures are easy — the model says something wrong and you catch it. The non-obvious failures are the ones that look right. Confident, fluent, structurally sound — and subtly incorrect in a way that only surfaces downstream. In an integration design, that might mean a pattern that works in most cases but fails under a specific load condition the model's training data underrepresented. The skill is building the review process that catches what the output scan misses.
The third is translating that into actual design decisions. Not AI is unreliable, add a human check — that is hedging, not architecture. The real question is: where in this system does non-determinism meet a high-cost decision, and what is the lightest-weight intervention that addresses that risk without destroying the value of using AI in the first place? This means mapping the cost of a wrong output at each decision point, then designing intervention only where that cost justifies it. That question requires both AI literacy and system design judgement — it sits at the intersection of the two.
Dr. Raj Ramesh's framework for enterprise architects identifies Technology Literacy as the first of seven essential skills. I thought I already had it. Turns out I had fluency, not the literacy.
The Eager Intern
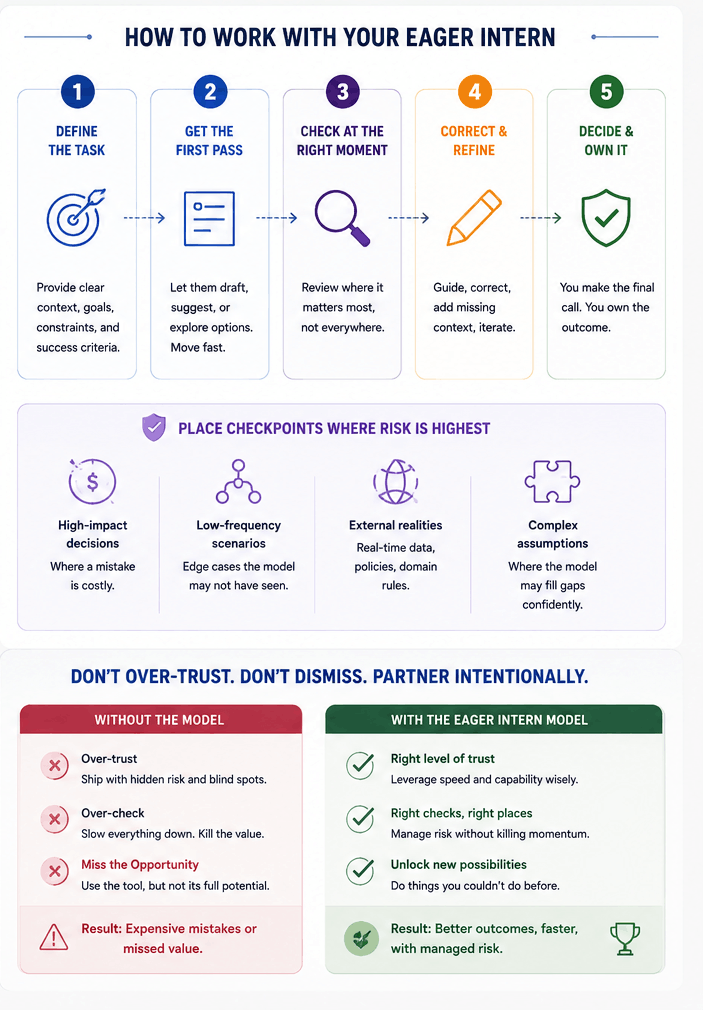
The mental model that shifted my relationship with these tools is one I refer as the Eager Intern. Brilliant. Fast. Genuinely impressive range of knowledge. Works hard, responds immediately, never complains about scope. And occasionally, confidently, fluently, without any visible sign of uncertainty — gets it completely wrong. The right response to an eager intern isn't to distrust everything they produce. It's to understand the shape of their blind spots and build your working relationship around that.
You don't ask them to make the final call on something where a confident mistake has a high cost. You do ask them to do the first pass on everything, because their first pass is better than nothing and often better than your first pass. You build in the check at the right moment, not at every moment — because checking everything defeats the purpose.
This is how I work with AI tools now. OpenAI for code generation and synthesis, Claude for longer reasoning tasks and writing, Copilot embedded in the flow. Each one has a shape to its reliability. The Eager Intern model stops me from either over-trusting or reflexively dismissing , both of which I've done, and both of which are expensive in their own way.
What I Didn't Know I Didn't Know
Here's the thing about the Copilot moment. It wasn't that I learned something new that day. It's that I had been fluent in the output without being literate in the mechanism.
I'd been reviewing AI-generated code the way I review any code — does it work, is it clean, does it follow the pattern. I was evaluating the product without understanding the process. And for most tools, that's fine. You don't need to understand how a database engine works to design a schema. But AI is different, because the failure modes are different. A database fails in ways that are visible and traceable. An AI system can fail in ways that look like success for months.
The literacy changes specific things. The questions I would ask in a vendor meeting are different now . training data, confidence model, behaviour at the edges of the use case. The risks I would flag in a design review are different — places where non-determinism meets a high-cost decision without adequate intervention. The conversations I can have with a data scientist are different — I can engage with the tradeoffs, not just the capabilities. None of that required becoming a data scientist. It required asking one question seriously: what is this thing actually doing?
And the further in I go, the more I realise that question is only the beginning. Once you understand what AI is, the harder problem appears. What does it mean to design a system around something whose behaviour you cannot fully predict? How do you architect for judgement rather than instruction? How do you draw a diagram for a component that makes decisions?
That is the question I am sitting with. And it is pulling me somewhere I did not expect — back to the fundamentals of what architecture actually is, and whether the discipline as I have practised it is still the right tool.
Thoughts? I'd love to hear them — find me on LinkedIn.